
 RDF - Resource Description Framework - the how-to for Cohere
RDF - Resource Description Framework - the how-to for Cohere
Table of Contents
What is RDF?
What does the Cohere RDF model look like?
How can I create some RDF for Cohere?
What is RDF?
RDF, the Resource Description Framework - developed by the World-Wide Web Consortium (W3C) - provides the foundation for metadata interoperability across different resource description communities.
RDF (Resource Description Framework) is a model for storing graphs of information. Given a set of resources, each resource being a thing, such as a person, a song, a web page or a bookmark, RDF is used to create relationships between these resources. Some people think of RDF as an XML language for describing data. However, this XML format is just a method of storing RDF in a file. If you are trying to learn RDF, it may be confusing to learn it via the XML syntax; instead, you should try first to understand the RDF model without looking at the XML syntax.
Think of a web or graph of interconnected nodes. The nodes are connected via various relationships. For example, let's say each node represents a person. Each person might be related to another person because they are siblings, parents, spouses, employees or enemies. Each interconnection is labeled with the relationship name. As a result we will have a densely populated graph of things and relations among things! For example, you can see below a graphical representation of an rdf structure describing actors and tv-shows.
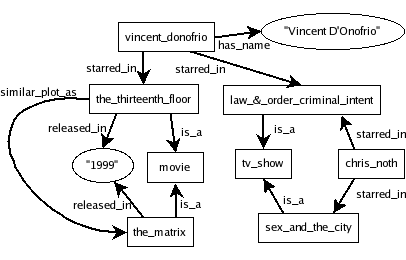
RDF may look difficult at first sight, but actually its model is really simple: it always consists of triples, i.e., sequences of *subject* => *predicate* => *object* statements. In order to find out more about RDF and how to create valid RDF files, check out the following resources:
- XUL-Planet: Introduction to the RDF Model
- XML.com: what is RDF?
- RDF in a nutshell
- Make you XML RDF-friendly
- An idiot's guide to RDF
- W3schools: RDF tutorial
- W3C RDF Validator
What does the Cohere RDF Model look like?
The Cohere data model is encoded in an ontology, which can be accessed at https://cohere.open.ac.uk/ontology/cohere.owl. It probably will not be very useful to open it in a web-browser,so we suggest you to use a tool like Protege' to visualize it. (just create a new project, select 'create from existing sources' and type in the cohere ontology url). Here we'll give you a quite detailed explanation of the entities in the Cohere world, and the relations among them. Let's see how these elements link up together.
Essentially, Cohere is about making connection among ideas, and linking them up to resources on the web: the key elements here are therefore the people who create such objects, the web resources we want to describe or refer to, the ideas we create and the connections used to relate the ideas.
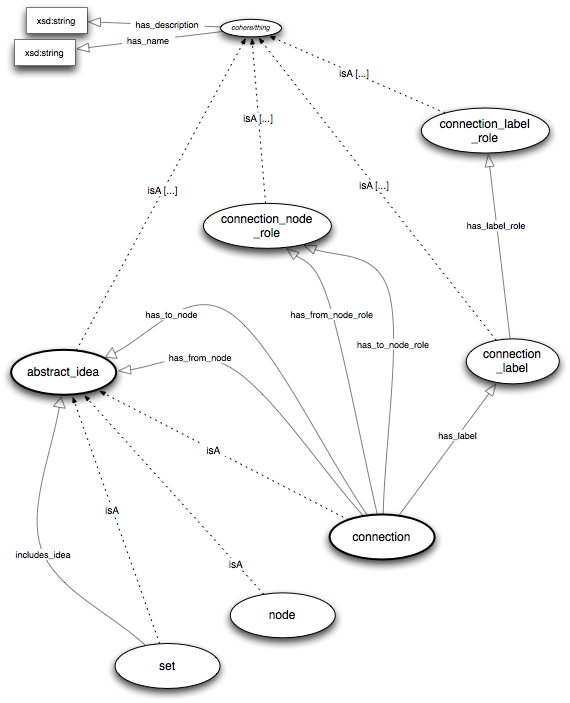
In the first figure it's possible to see the modeling of the PERSON , WEBSITE, IMAGE and IDEA classes (images can be added to ideas and persons as a mean of describing them). Notice how an ABSTRACT_IDEA is a complex entity, which subsumes NODE, CONNECTION and SET. This is needed (see below) for being able to create connections at various levels of abstraction: e.g. by linking a node (i.e. a simple idea) and a connection, two nodes or a node and a set of connections. The result of this is a mechanism that supports the creation of complex networks of nested ideas.

The second figure shows the modeling of the CONNECTION class, which is the element Cohere provides in order to create relations among ideas. The important thing to remember here is that an idea only plays a role (e.g. premise, conclusion, example etc.) in the context of a connection. Therefore a connection class, beyond having the from_node and to_node properties, has also the has_from_node_role and has_to_node_role properties. By doing so, the role of a node in a connection is stored together with the connection, and not with the node itself. Further, a connection contains also a connection_label which is the edge connecting the two elements. Connections have three default roles you can choose from, 'positive', 'negative' and 'neutral', which are represented as instance of the connection_label_role class. If left unspecified, they will be classified as neutral.
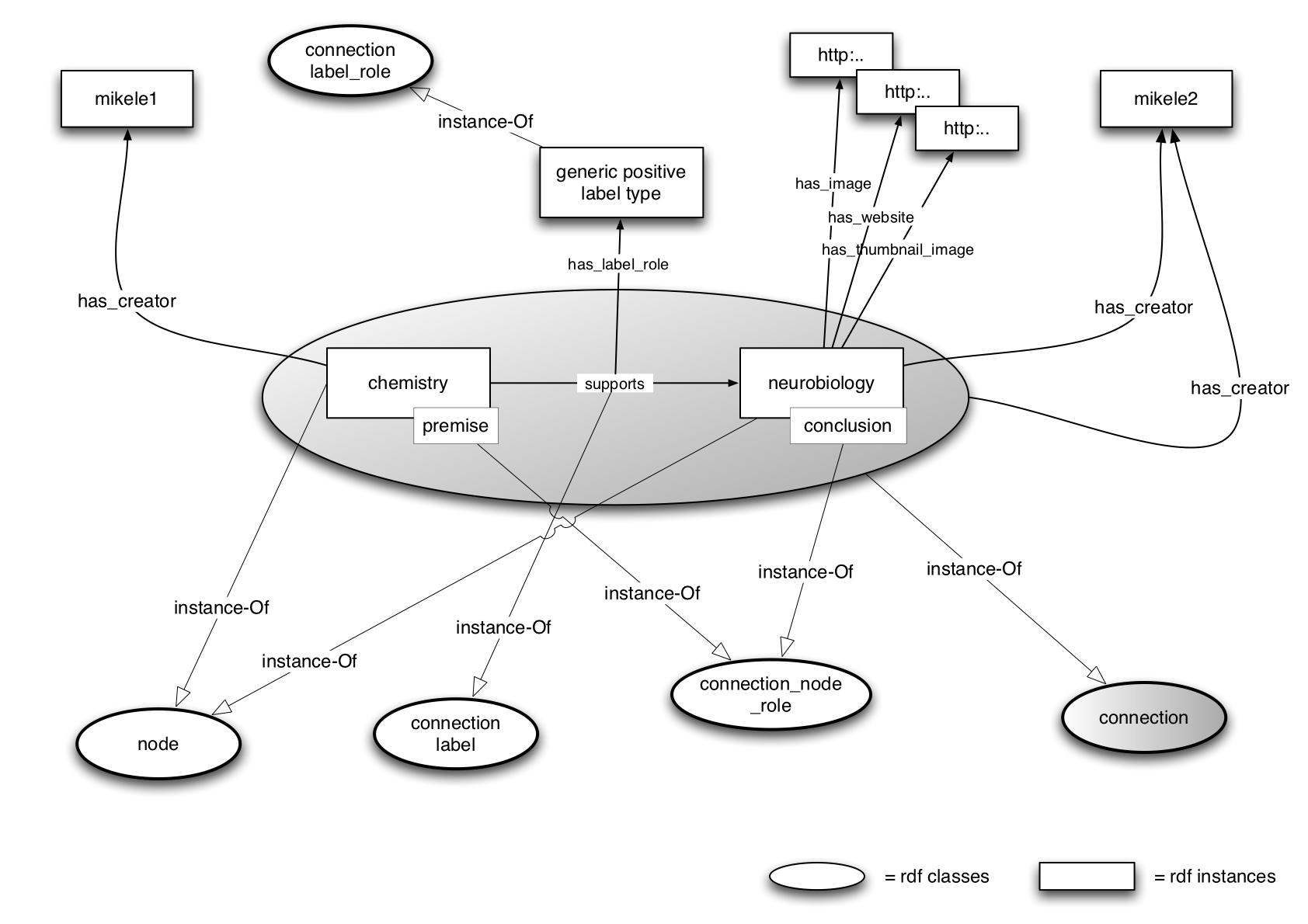
The third figure shows an example-instantiation. Here we have a simple connection between two ideas: chemistry and neurobiology. Notice how the creation of the triple [chemistry -> supports -> neurobiology] involves the instantiation of several other classes!
How can I create RDF for Cohere?
Okay .. it's time to get more practical now.
We'll create some RDF/XML code expressing the instantiation example on fig.3. If you're reading this, you probably need to upload large data files containing ideas and connections into Cohere, so you'll be better off creating the RDF-XML programmatically with a script or some other library (you can find here a good list of the available libraries). Now instead, for the sake of explanation, we'll do all this tedious work manually... :-)
One last thing to remember (if you're not familiar with the rdf family of languages): in rdf
the statements do not have to respect a fixed order; as a result, usually your automatically-generated code will be quite difficult to read for humans
(e.g. some statements may refer to objects which are created only at the end of the file). Also, resources can be created within other resources: that means that
new resources do not all have to be created at the top-level.
For example, we could have the <person rdf:ID="person_mikele1"\> created within the description
of another resource, e.g. an instance of a connection link: <connection_link rdf:ID="connection_link_chemistry_TO_neurobiology"> . This may appear very
confusing, cause the person and the connection we are talking about are not strictly or exclusively related to each other. For a gentle and quick introduction to
rdf, make sure you had a look at one of the links above... Enjoy!
An RDF/XML file usually starts with a namespace declaration. This is basically where we're declaring what vocabularies we are using. For example, here we specify that with the prefix ns1 we are actually referring to the namespace https://cohere.open.ac.uk/ontology/cohere.owl, which is the cohere ontology. This will become useful later on, when referring to the classes in the Cohere model, because we can just use the prefix notation instead of writing every time the whole url (of course, it could have been done the 'verbose' way too). Even if you do not really want to understand what this is about, please make sure that the following code stays at the top of your rdf file, otherwise you surely will not be able to import your data!
<?xml version="1.0" encoding="UTF-8" ?> <rdf:RDF xml:base="https://cohere.open.ac.uk/ontology/cohere.owl#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:xsd="http://www.w3.org/2001/XMLSchema#" xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#" xmlns:ns1="https://cohere.open.ac.uk/ontology/cohere.owl#">
Now we can start defining our data. First of all we need to instantiate all the 'basic' elements of our example. That is, websites, users and images.
In the case of the websites, we will have the following:
<ns1:website rdf:ID="website_49_chemistry"> <ns1:has_description rdf:datatype="http://www.w3.org/2001/XMLSchema#string">my favourite chemistry website</ns1:has_description> <has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">http://chemistry_website.com</ns1:has_url> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">the website of chemistry</ns1:has_name> </ns1:website> <ns1:website rdf:ID="website_neurobiology"> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">the website of neurobiology</ns1:has_name> <ns1:has_description rdf:datatype="http://www.w3.org/2001/XMLSchema#string">neurobiology website</ns1:has_description> <has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">http://neurobiology_website.com</ns1:has_url> </ns1:website> <ns1:website rdf:ID="website_mikele2"> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">mikele2's homepage</ns1:has_name> <has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">www.mikele2.com</ns1:has_url> </ns1:website> <ns1:website rdf:ID="website_42_mikele1"> <has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">www.mikele1.com</ns1:has_url> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">mikele's homepage</ns1:has_name> </ns1:website>
Now it's the turn of the users:
<ns1:cohere_user rdf:ID="person_mikele1"> <ns1:has_homepage rdf:resource="#website_42_mikele1"/> <ns1:has_email_address rdf:datatype="http://www.w3.org/2001/XMLSchema#string">mikele1@open.ac.uk</ns1:has_email_address> <ns1:has_description rdf:datatype="http://www.w3.org/2001/XMLSchema#string">one of the aliases of this ontology's creator</ns1:has_description> <ns1:has_depiction rdf:resource="#image_43_mikele1"/> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">mikele1</ns1:has_name> </ns1:cohere_user> <ns1:cohere_user rdf:ID="person_mikele2"> <ns1:has_homepage rdf:resource="#website_mikele2"/> <ns1:has_email_address rdf:datatype="http://www.w3.org/2001/XMLSchema#string">mikele2@open.ac.uk</ns1:has_email_address> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">mikele2</ns1:has_name> <ns1:has_description rdf:datatype="http://www.w3.org/2001/XMLSchema#string">another one of the aliases of this ontology's creator</ns1:has_description> <ns1:has_depiction rdf:resource="#image_mikele2"/> </ns1:cohere_user>
Finally, let's create some instances for the images as well.
<ns1:image rdf:ID="image_43_mikele1"> <ns1:has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">http://mikele1.tiff</ns1:has_url> </ns1:image> <ns1:image rdf:ID="image_mikele2"> <ns1:has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">http://mikele2.tiff</ns1:has_url> </ns1:image> <ns1:image rdf:ID="image_52_neurobiology"> <ns1:has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">http://neurobiologyimage.tiff</ns1:has_url> </ns1:image> <ns1:image rdf:ID="thumbnail_image_neurobiology"> <ns1:has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">http://thumbnail_neurobiology.tiff</ns1:has_url> </ns1:image> <ns1:image rdf:ID="image_47_chemistry"> <ns1:has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">http://chemistryimage.tiff</ns1:has_url> </ns1:image> <ns1:image rdf:ID="thumbnail_image_48_neurobiology"> <ns1:has_url rdf:datatype="http://www.w3.org/2001/XMLSchema#string">http://thumbnail_neurobiology.tiff</ns1:has_url> </ns1:image>
Now we have all the elements for creating the node instances, that is, the two atomic ideas which are connected together, i.e. neurobiology and chemistry. Notice how the already existing object are referenced to by using the rdf:resource=#... syntax.
<ns1:node rdf:ID="simple_idea_51_neurobiology"> <ns1:has_creator rdf:resource="#person_mikele2"/> <ns1:has_creation_date rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">2008-02-19T14:34:49</ns1:has_creation_date> <ns1:has_image rdf:resource="#image_52_neurobiology"/> <ns1:has_website rdf:resource="#website_neurobiology"/> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">neurobiology</ns1:has_name> <ns1:has_thumbnail_image rdf:resource="#thumbnail_image_neurobiology"/> <ns1:has_description rdf:datatype="http://www.w3.org/2001/XMLSchema#string">the idea of neurobiology, the discipline</ns1:has_description> </ns1:node> <ns1:node rdf:ID="simple_idea_20_chemistry"> <ns1:has_creation_date rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">2008-02-19T14:34:49</ns1:has_creation_date> <ns1:has_creator rdf:resource="#person_mikele1"/> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">chemistry</ns1:has_name> <ns1:has_description rdf:datatype="http://www.w3.org/2001/XMLSchema#string">the idea of chemistry, the discipline</ns1:has_description> <ns1:has_image rdf:resource="#image_47_chemistry"/> <ns1:has_website rdf:resource="#website_49_chemistry"/> <ns1:has_thumbnail_image rdf:resource="#thumbnail_image_48_neurobiology"/> </ns1:node>
Quite straighforward up to now, uh?
So we're getting to the final bit, which is creating the connection instance. Before doing that, though,
we have to create some more basic elements of the connection object. These are the label connecting the two nodes and the label-role specifying
whether the label stands for a *positive*, *negative* or *neutral* relationship.
Remember that is not compulsory to create label-roles
when you upload a cohere-rdf file!
When Cohere finds a label without an associated role it will automatically attach a *neutral* role
to it. Also, if the specified role's name does not match one of the three default ones (i.e. 'positive', 'negative' and 'neutral')
it won't be recognized as a valid option and will be transformed into a *neutral* label-role. This is only a temporary
solution - we are working for extending this functionality so to let users have complete freedom in the creation of label-roles.
For example, in the following code we are creating a valid *positive* label-role instance, which is then used to describe the label with name 'supports_idea'.
<ns1:connection_label_role rdf:ID="connection_label_role_1_positive"> <ns1:has_description rdf:datatype="http://www.w3.org/2001/XMLSchema#string">instance representing the positive role</ns1:has_description> <ns1:has_creator rdf:resource="#person_mikele1"/> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">positive</ns1:has_name> </ns1:connection_label_role<> <ns1:connection_label rdf:ID="connection_link_chemistry_TO_neurobiology"> <ns1:has_label_role rdf:resource="#connection_label_role_1_positive"/> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">supports_idea</ns1:has_name> </ns1:connection_label>
The other type or roles we might want to create are the roles the nodes have in the connection. For example, we can say that the first node acts as a premise, and the second as a conclusion. Or that the first one is the evidence, while the second is an objection, and so on... Cohere has a set of pre-defined roles to use, but if you want you can always create a new node-role if it suits your needs best.
<ns1:connection_node_role rdf:ID="connection_node_type_conclusion"> <ns1:has_creator rdf:resource="#person_mikele1"/> <ns1:has_description rdf:datatype="http://www.w3.org/2001/XMLSchema#string">a conclusion in some argumentation schema</ns1:has_description> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">conclusion</ns1:has_name> </ns1:connection_node_role> <ns1:connection_node_role rdf:ID="connection_node_type_premise"> <ns1:has_creator rdf:resource="#person_mikele1"/> <ns1:has_name rdf:datatype="http://www.w3.org/2001/XMLSchema#string">premise</ns1:has_name> <ns1:has_description rdf:datatype="http://www.w3.org/2001/XMLSchema#string">a premise in some argumentation schema</ns1:has_description> </ns1:connection_node_role>
Finally, now we have all the elements needed to instantiate the connection class!
<ns1:connection rdf:ID="connection_chemistry_to_neurobiology"> <ns1:has_creator rdf:resource="#person_mikele1"/> <ns1:has_creation_date rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">2008-02-19T14:41:50</ns1:has_creation_date> <ns1:has_to_node_role rdf:resource="#connection_node_type_conclusion"/> <ns1:has_to_node rdf:resource="#simple_idea_51_neurobiology"/> <ns1:has_from_node_role rdf:resource="#connection_node_type_premise"/> <ns1:has_from_node rdf:resource="#simple_idea_20_chemistry"/> <ns1:has_label rdf:resource="#connection_link_chemistry_TO_neurobiology"/> </ns1:connection>
Last but not least, we have to close the rdf tag....
</rdf:RDF>
IMPORTANT: once you've created the RDF of the data you want to import into Cohere, it's always a good practice to validate it before trying to import it! For this purpose, you can use the W3C RDF Validator.